
ML的4个指标——准确率、精确率、召回率与F1 score
机器学习的分类任务中,准确率(accuracy)、精确率(precision)、召回率(recall)与F1 score是常见的4个评估指标。之前对于这些指标有粗略的了解,如今加深一下理解
混淆矩阵(Confusion Matrix)
混淆矩阵如图所示:
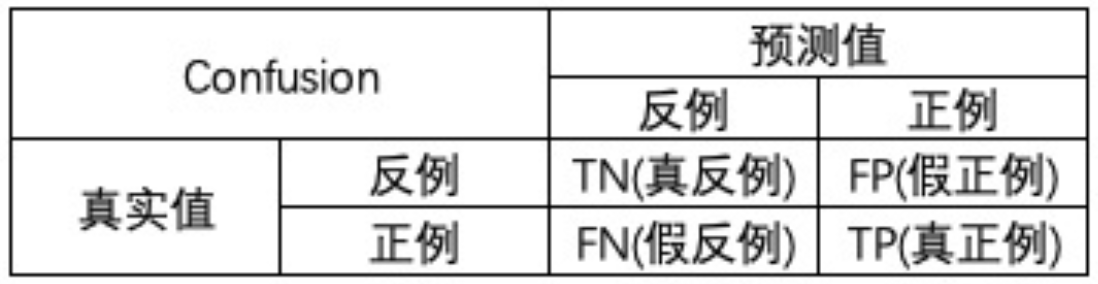
四个值的具体解释为:
- TP(True Positive):被正确预测的正例。即真实值为正,预测值为正
- TN:被正确预测的反例
- FP:被错误预测的正例。即真实值为负,预测值为正
- FN(False Negative):被错误预测的反例
即,第一个字母指的是预测正误,第二个字母指的是预测结果
准确率(Accuracy)
表示分类正确的样本占总样本个数的比例,即:\[Accuracy=\frac{TP+TN}{TP+TN+FP+FN}\]
这是最直接的指标,但缺陷在于:当不同类别的样本占比不平衡时,占比大的类别会是影响准确率的最主要因素
举例:当数据集中99%为正例,那么只要分类器一直预测为正,即可达到很高的准确率
因此只有当数据集中各个类别样本比例均衡时,准确率才有较大的参考意义
精确率(Precision)
表示被预测为正的样本中,实际为正样本的比例。即:\[Precision=\frac{TP}{TP+FP}\]
个人理解一下:
- 首先,能够影响精确率的只有被预测为正的样本
- 被预测为正的样本中,如果其他不变
- TP增大(被正确地判断为正的样本增多),精确率变大
- FP增大(被错误地判断为正的样本增多),精确率变小
所以,精确率越高,将负样本误判为正的概率越小
换句话说,提升精确率,是为了不将负样本误判为正(不错判)
召回率(Recall)
表示实际为正的样本中,被预测为正的样本所占比例。即:\[Recall=\frac{TP}{TP+FN}\]
可以发现,上述文字定义就是将精确率的文字定义倒转过来
个人理解一下:
- 首先,能够影响召回率的只有实际为正的样本
- 实际为正的样本中,如果其他不变:
- TP增大(被正确地判断为正的样本增多),召回率变大
- FN增大(被错误地判断为负的样本增多),召回率变小
所以,召回率越高,将正样本误判为负的概率越小
换句话说,提高精确率,是为了不将正样本误判为负(不漏判)
F1 Score
通过上述分析可以发现,精确率和召回率是两难全的。综合一下 两者,F1 score是精确率和召回率的一个加权平均:\[F1=2\times\frac{Precision\times Recall}{Precision+Recall}\]
因为精确率体现分类器不错判的能力,召回率体现不漏判的能力,所以F1 Score越高,模型越稳健
参考
https://zhuanlan.zhihu.com/p/405658103